


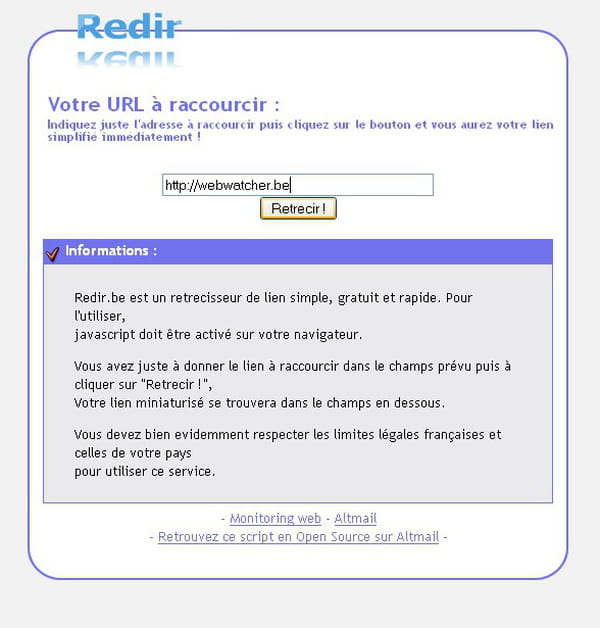
Raccourcisseur d'url
Description
Voici une petite source permettant de créer des liens courts à partir de liens complexes.
C'est bien entendu juste une base, vous pouvez l'améliorer si vous le souhaitez.
Tous vos conseils sont les bienvenus
La source est dans le zip,
vous pouvez tester la démo sur http://redir.be
Pour installer cette source il faut une base de donnée MySQL.
Elle peut également nécessiter le cache APC selon la configuration.
C'est bien entendu juste une base, vous pouvez l'améliorer si vous le souhaitez.
Tous vos conseils sont les bienvenus
La source est dans le zip,
vous pouvez tester la démo sur http://redir.be
Pour installer cette source il faut une base de donnée MySQL.
Elle peut également nécessiter le cache APC selon la configuration.
Vous n'êtes pas encore membre ?
inscrivez-vous, c'est gratuit et ça prend moins d'une minute !
Les membres obtiennent plus de réponses que les utilisateurs anonymes.
Le fait d'être membre vous permet d'avoir un suivi détaillé de vos demandes et codes sources.
Le fait d'être membre vous permet d'avoir des options supplémentaires.