


Bien explique: exemple de reseau de neurone
Description
il s'agit d'un réseau de neurone qui ne fait que approximer
xor
exponentielle
carré
produit
somme
les explications sur l'algortihme de base du réseau de neurone:
http://www.hacking.free.fr/paris8/Backpropagation.htm
l'intéret est que j'ai écrit 3 pages pour expliquer comment il fonctione, car j'ai dû faire un vrai travail de détective pour réussir à le programmer
notatement je me suis servi d'une source qui marchait bien pour le xor (c'est pas courrant !)
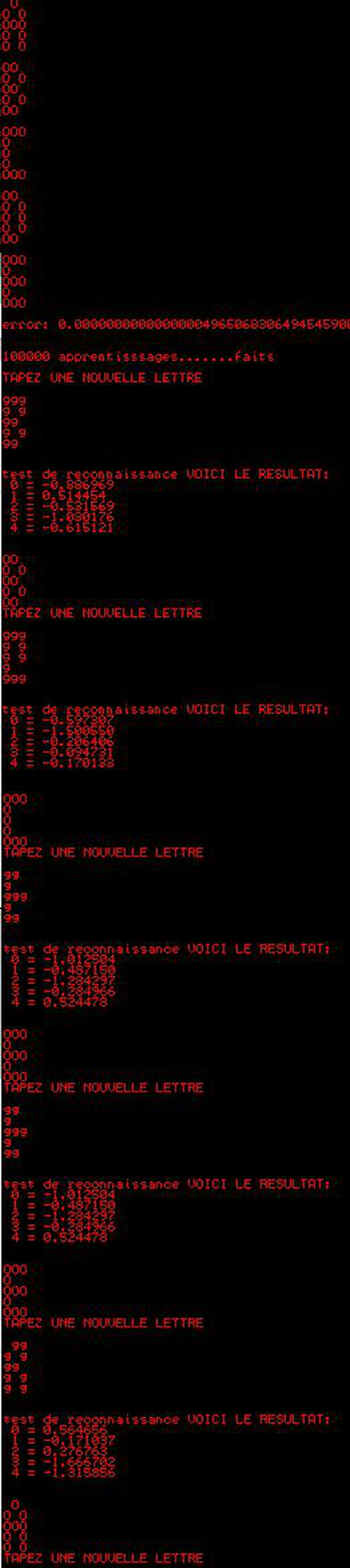
pour la détection de lettres :
comme vous pouvez le voir dans le screenshot les résultats sont déja amusants avec seulement 5 exemples "bruités" avec un random
les main sont dans le zip
xor
exponentielle
carré
produit
somme
les explications sur l'algortihme de base du réseau de neurone:
http://www.hacking.free.fr/paris8/Backpropagation.htm
l'intéret est que j'ai écrit 3 pages pour expliquer comment il fonctione, car j'ai dû faire un vrai travail de détective pour réussir à le programmer
notatement je me suis servi d'une source qui marchait bien pour le xor (c'est pas courrant !)
pour la détection de lettres :
comme vous pouvez le voir dans le screenshot les résultats sont déja amusants avec seulement 5 exemples "bruités" avec un random
Source / Exemple :
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <time.h>
typedef double mlp_float;
typedef struct {
mlp_float *poids_synaptique;
mlp_float *valeur_neurone;
mlp_float *valeur_erreur_neurone;
mlp_float *neurone_entree;
mlp_float *neurone_sortie;
mlp_float *valeur_erreur_sortie;
int *index_couche;
int *taille_couche;
int *index_synapse;
int nombre_couche;
int nombre_neurone;
int nombre_synapse;
int taille_couche_entree;
int taille_couche_sortie;
} mlp;
static mlp_float MAGICAL_WEIGHT_NUMBER = 1.0f;
static mlp_float MAGICAL_LEARNING_NUMBER = 0.09f;
mlp *create_mlp(int nombre_couche, int *taille_couche) {
mlp *reseau = malloc(sizeof * reseau);
reseau->nombre_couche = nombre_couche;
reseau->taille_couche = malloc(sizeof * reseau->taille_couche * reseau->nombre_couche);
reseau->index_couche = malloc(sizeof * reseau->index_couche * reseau->nombre_couche);
int i;
reseau->nombre_neurone = 0;
for (i = 0; i < nombre_couche; i++) {
reseau->taille_couche[i] = taille_couche[i];
reseau->index_couche[i] = reseau->nombre_neurone;
reseau->nombre_neurone += taille_couche[i];
}
reseau->valeur_neurone = malloc(sizeof * reseau->valeur_neurone * reseau->nombre_neurone);
reseau->valeur_erreur_neurone = malloc(sizeof * reseau->valeur_erreur_neurone * reseau->nombre_neurone);
reseau->taille_couche_entree = taille_couche[0];
reseau->taille_couche_sortie = taille_couche[nombre_couche-1];
reseau->neurone_entree = reseau->valeur_neurone;
reseau->neurone_sortie = &reseau->valeur_neurone[reseau->index_couche[nombre_couche-1]];
reseau->valeur_erreur_sortie = &reseau->valeur_erreur_neurone[reseau->index_couche[nombre_couche-1]];
reseau->index_synapse = malloc(sizeof * reseau->index_synapse * (reseau->nombre_couche-1));
reseau->nombre_synapse = 0;
for (i = 0; i < nombre_couche - 1; i++) {
reseau->index_synapse[i] = reseau->nombre_synapse;
reseau->nombre_synapse += (reseau->taille_couche[i]+1) * reseau->taille_couche[i+1];
}
reseau->poids_synaptique = malloc(sizeof * reseau->poids_synaptique * reseau->nombre_synapse);
for (i = 0; i < reseau->nombre_synapse; i++) {
reseau->poids_synaptique[i] = MAGICAL_WEIGHT_NUMBER * (mlp_float)rand() / RAND_MAX - MAGICAL_WEIGHT_NUMBER/2;
}
return reseau;
}
void free_mlp (mlp *reseau) {
free(reseau->taille_couche);
free(reseau->index_couche);
free(reseau->valeur_neurone);
free(reseau->valeur_erreur_neurone);
free(reseau->index_synapse);
free(reseau->poids_synaptique);
free(reseau);
}
void set_mlp (mlp * reseau, mlp_float *vecteur) {
if (vecteur != NULL) {
int i;
for (i = 0; i < reseau->taille_couche_entree; i++) {
reseau->neurone_entree[i] = vecteur[i];
}
}
int i;
int index_synapse;
index_synapse = 0;
for (i = 1; i < reseau->nombre_couche; i++) {
int j;
for (j = reseau->index_couche[i]; j < reseau->index_couche[i] + reseau->taille_couche[i]; j++) {
mlp_float somme_ponderee = 0.0;
int k;
for (k = reseau->index_couche[i-1]; k < reseau->index_couche[i-1] + reseau->taille_couche[i-1]; k++) {
somme_ponderee += reseau->valeur_neurone[k] * reseau->poids_synaptique[index_synapse];
index_synapse++;
}
somme_ponderee += reseau->poids_synaptique[index_synapse];
index_synapse++;
reseau->valeur_neurone[j] = somme_ponderee;
if (i != reseau->nombre_couche - 1) reseau->valeur_neurone[j] = tanh(reseau->valeur_neurone[j]);
}
}
}
void get_mlp (mlp *reseau, mlp_float *vecteur) {
int i;
for (i = 0; i < reseau->taille_couche_sortie; i++) {
vecteur[i] = reseau->neurone_sortie[i];
}
}
void learn_mlp (mlp *reseau, mlp_float *desired_out) {
int i;
mlp_float global_error = 0;
int index_synapse = reseau->index_synapse[reseau->nombre_couche-2];
for (i = 0; i < reseau->taille_couche_sortie; i++) {
reseau->valeur_erreur_sortie[i] = reseau->neurone_sortie[i] - desired_out[i];
int j;
for (j = reseau->index_couche[reseau->nombre_couche-2]; j < reseau->index_couche[reseau->nombre_couche-2] + reseau->taille_couche[reseau->nombre_couche-2]; j++) {
mlp_float weightChange;
weightChange = MAGICAL_LEARNING_NUMBER * reseau->valeur_erreur_sortie[i] * reseau->valeur_neurone[j];
reseau->poids_synaptique[index_synapse] -= weightChange;
if (reseau->poids_synaptique[index_synapse] > 5) reseau->poids_synaptique[index_synapse] = 5;
if (reseau->poids_synaptique[index_synapse] < -5) reseau->poids_synaptique[index_synapse] = -5;
index_synapse++;
}
mlp_float weightChange;
weightChange = MAGICAL_LEARNING_NUMBER * reseau->valeur_erreur_sortie[i];
reseau->poids_synaptique[index_synapse] -= weightChange;
if (reseau->poids_synaptique[index_synapse] > 5) reseau->poids_synaptique[index_synapse] = 5;
if (reseau->poids_synaptique[index_synapse] < -5) reseau->poids_synaptique[index_synapse] = -5;
index_synapse++;
}
for (i = reseau->nombre_couche - 2; i > 0; i--) {
int j;
int jj= 0;
int index_synapse = reseau->index_synapse[i-1];
for (j = reseau->index_couche[i]; j < reseau->index_couche[i] + reseau->taille_couche[i]; j++,jj++) {
int k;
int index_synapse2 = reseau->index_synapse[i] + jj;
reseau->valeur_erreur_neurone[j] = 0;
for (k = reseau->index_couche[i+1]; k < reseau->index_couche[i+1] + reseau->taille_couche[i+1]; k++) {
reseau->valeur_erreur_neurone[j] += reseau->poids_synaptique[index_synapse2] * reseau->valeur_erreur_neurone[k];
index_synapse2+=reseau->taille_couche[i]+1;
}
for (k = reseau->index_couche[i-1]; k < reseau->index_couche[i-1] + reseau->taille_couche[i-1]; k++) {
mlp_float weightChange;
weightChange = 1.0 - reseau->valeur_neurone[j] * reseau->valeur_neurone[j];
weightChange *= reseau->valeur_erreur_neurone[j] * MAGICAL_LEARNING_NUMBER;
weightChange *= reseau->valeur_neurone[k];
reseau->poids_synaptique[index_synapse] -= weightChange;
index_synapse++;
}
mlp_float weightChange;
weightChange = 1.0 - reseau->valeur_neurone[j] * reseau->valeur_neurone[j];
weightChange *= reseau->valeur_erreur_neurone[j] * MAGICAL_LEARNING_NUMBER;
reseau->poids_synaptique[index_synapse] -= weightChange;
index_synapse++;
}
}
}
Conclusion :
les main sont dans le zip
Codes Sources
A voir également
- Bien explique: exemple de reseau de neurone
- Bien preparer entretien technique java - Forum Java
- J'ai pas bien saisi en arabe ✓ - Forum Delphi / Pascal
- Test de recrutement classique en tant qu'Ingénieur ou Architecte .Net avec quelques notions Java - Conseils pratiques -C# / .NET
- Allez viens on est bien gif - Forum VB.NET
- Bien gras mots fléchés ✓ - Forum Delphi / Pascal
Vous n'êtes pas encore membre ?
inscrivez-vous, c'est gratuit et ça prend moins d'une minute !
Les membres obtiennent plus de réponses que les utilisateurs anonymes.
Le fait d'être membre vous permet d'avoir un suivi détaillé de vos demandes et codes sources.
Le fait d'être membre vous permet d'avoir des options supplémentaires.