


Split sql sans table temporaire
Description
Voici une fonction qui permet de splitter les données contenues dans une seule colonne avec séparateur, sans passer par une table temporaire.
Voici le principe, qui n'est pas évident à expliquer.
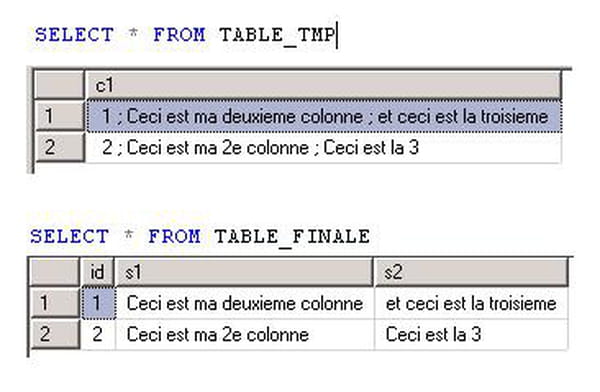
Si on regarde l'instruction SQL générée :
SELECT
RTRIM(LTRIM(SUBSTRING(COLUMN_1,1,CHARINDEX(' ; ',COLUMN_1,1)-1))),
RTRIM(LTRIM(SUBSTRING(COLUMN_1,1+LEN(SUBSTRING(COLUMN_1,1,CHARINDEX(' ; ',COLUMN_1,1)-1))+2,(CHARINDEX(' ; ',COLUMN_1,1+LEN(SUBSTRING(COLUMN_1,1,CHARINDEX(' ; ',COLUMN_1,1)-1))+2)-(1+LEN(SUBSTRING(COLUMN_1,1,CHARINDEX(' ; ',COLUMN_1,1)-1))+2))))),
RTRIM(LTRIM(SUBSTRING(COLUMN_1,1+LEN(SUBSTRING(COLUMN_1,1,CHARINDEX(' ; ',COLUMN_1,1)-1))+2+LEN(SUBSTRING(COLUMN_1,1+LEN(SUBSTRING(COLUMN_1,1,CHARINDEX(' ; ',COLUMN_1,1)-1))+2,(CHARINDEX(' ; ',COLUMN_1,1+LEN(SUBSTRING(COLUMN_1,1,CHARINDEX(' ; ',COLUMN_1,1)-1))+2)-(1+LEN(SUBSTRING(COLUMN_1,1,CHARINDEX(' ; ',COLUMN_1,1)-1))+2))))+2,999)))
FROM TABLE_SOURCE
On remarque que code qui permet de retourner la 1ère chaîne :
SUBSTRING(COLUMN_1, 1, CHARINDEX(' ; ',COLUMN_1,1)-1)
se retrouve dans le calcul de la recherche du 2ème séparateur. En effet, il suffit de faire un LEN() de cette instruction pour savoir où commencer à chercher la prochaine occurrence du séparateur.
Ainsi de suite, l'instruction qui a permis de trouver la chaîne se retrouve dans le calcul de la chaîne suivante (ce qu'on calcule c'est la position des occurrences du séparateur).
En fait, c'est une requête fractale ^^
Le gros avantage de cette méthode est la rapidité d'exécution, par rapport à une solution classique dans laquelle, à chaque boucle, on sauvegarde les morceaux de chaînes splittées dans une table temporaire, ce qui peut très rapidement générer des milliers d'insert.
La seule limite qui existe est la longueur maximale de la requête générée.
Source / Exemple :
// Code source complet dans le zip !
public string SqlSplitSeparateur(ArrayList champsList, string separateur, int idxFirstCol)
{
string currentIndex = idxFirstCol.ToString(); // index de la 1ère colonne dans le fichier
string subStrPrec = "";
string colLen;
string sqlSelect = "";
int i = 0;
foreach (Champ champ in champsList)
{
i++;
if (i == 1)
{
// Pour la 1ère ligne, aller jusqu'à la 1ere occurence du séparateur
subStrPrec = "SUBSTRING(" +
TMP_COL + "," +
idxFirstCol + "," +
"CHARINDEX('" + separateur + "'," + TMP_COL + "," + idxFirstCol + ")-" + idxFirstCol + ")";
}
else
{
// Lignes suivantes : calcul de la longueur de la colonne (de currentIndex au prochain séparateur / fin)
if (i < champsList.Count)
colLen = "(CHARINDEX('" + separateur + "'," + TMP_COL + "," + currentIndex + ")" + "-(" + currentIndex + "))";
else
colLen = "999"; // Dernière colonne : aller jusqu'en fin de ligne (il n'y a plus de séparateur !) - NB : on pourrait le calculer : colLen=LEN(TMP_COL)-currentIndex
subStrPrec = "SUBSTRING(" + TMP_COL + "," + currentIndex + "," + colLen + ")";
}
sqlSelect += "RTRIM(LTRIM(" + subStrPrec + ")),";
// MAJ de la position dans la ligne
currentIndex += "+LEN(" + subStrPrec + ")+" + separateur.Length;
}
sqlSelect = sqlSelect.Remove(sqlSelect.LastIndexOf(','), 1); // On retire la virgule de la fin
return "SELECT " + sqlSelect + " FROM " + TABLE_TMP;
}
Conclusion :
Voici le principe, qui n'est pas évident à expliquer.
Si on regarde l'instruction SQL générée :
SELECT
RTRIM(LTRIM(SUBSTRING(COLUMN_1,1,CHARINDEX(' ; ',COLUMN_1,1)-1))),
RTRIM(LTRIM(SUBSTRING(COLUMN_1,1+LEN(SUBSTRING(COLUMN_1,1,CHARINDEX(' ; ',COLUMN_1,1)-1))+2,(CHARINDEX(' ; ',COLUMN_1,1+LEN(SUBSTRING(COLUMN_1,1,CHARINDEX(' ; ',COLUMN_1,1)-1))+2)-(1+LEN(SUBSTRING(COLUMN_1,1,CHARINDEX(' ; ',COLUMN_1,1)-1))+2))))),
RTRIM(LTRIM(SUBSTRING(COLUMN_1,1+LEN(SUBSTRING(COLUMN_1,1,CHARINDEX(' ; ',COLUMN_1,1)-1))+2+LEN(SUBSTRING(COLUMN_1,1+LEN(SUBSTRING(COLUMN_1,1,CHARINDEX(' ; ',COLUMN_1,1)-1))+2,(CHARINDEX(' ; ',COLUMN_1,1+LEN(SUBSTRING(COLUMN_1,1,CHARINDEX(' ; ',COLUMN_1,1)-1))+2)-(1+LEN(SUBSTRING(COLUMN_1,1,CHARINDEX(' ; ',COLUMN_1,1)-1))+2))))+2,999)))
FROM TABLE_SOURCE
On remarque que code qui permet de retourner la 1ère chaîne :
SUBSTRING(COLUMN_1, 1, CHARINDEX(' ; ',COLUMN_1,1)-1)
se retrouve dans le calcul de la recherche du 2ème séparateur. En effet, il suffit de faire un LEN() de cette instruction pour savoir où commencer à chercher la prochaine occurrence du séparateur.
Ainsi de suite, l'instruction qui a permis de trouver la chaîne se retrouve dans le calcul de la chaîne suivante (ce qu'on calcule c'est la position des occurrences du séparateur).
En fait, c'est une requête fractale ^^
Le gros avantage de cette méthode est la rapidité d'exécution, par rapport à une solution classique dans laquelle, à chaque boucle, on sauvegarde les morceaux de chaînes splittées dans une table temporaire, ce qui peut très rapidement générer des milliers d'insert.
La seule limite qui existe est la longueur maximale de la requête générée.
Codes Sources
A voir également
- Split sql sans table temporaire
- Php table - Conseils pratiques -PHP
- Decimal sql - Forum SQL
- Afficher les colonnes d'une table sql ✓ - Forum SQL
- Vb.net split ✓ - Forum PDA
- C# split ✓ - Forum C# / .NET
Vous n'êtes pas encore membre ?
inscrivez-vous, c'est gratuit et ça prend moins d'une minute !
Les membres obtiennent plus de réponses que les utilisateurs anonymes.
Le fait d'être membre vous permet d'avoir un suivi détaillé de vos demandes et codes sources.
Le fait d'être membre vous permet d'avoir des options supplémentaires.