


Completion de texte via un Radix Tree
Description
Suite à une question sur le forum: http://codes-sources.commentcamarche.net/forum/affich-10060089-feedback-sur-programme-c
=== Principe ===
Un Radix Tree est un Trie Tree amélioré. Cette structure de donnée permet de faire tenir une liste de mots dans un arbre compact. C'est très utilisé pour des dictionnaires, des numéros de téléphones, etc...
Sa fonction première est de dire si un mot est présent dans la collection, mais c'est aussi souvent employé pour faire de la complétion (c'est-à-dire donner tous les mots commençant par celui que l'on vient de fournir).
Par exemple pour les mots:
- tete
- testons
- testosterone
- testa
- tester
Le trie tree associé serait:
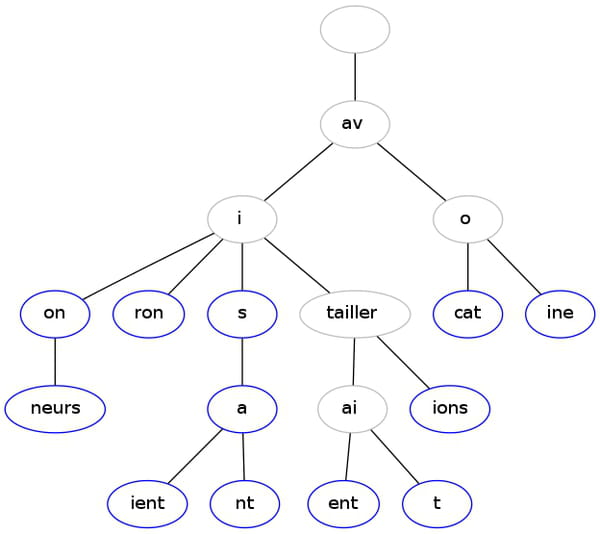
Et le radix tree:
=== Projet ===
Ce projet est composé de 3 exécutables:
- radix-completion: Lorsqu'on lui fournit un mot, il dit si celui-ci est présent dans le dictionnaire fourni et il donne la liste des mots qui commencent par celui-ci.
- radix-test: Tests unitaires pour vérifier que la collection a été implémentée correctement.
- radix-bench: Teste les performances de différentes collections (utilisé pour fournir les données ci-dessous).
À noter qu'il est possible de générer un fichier *.dot de l'arbre, afin de le faire dessiner par dotty (d'ailleurs utilisé pour créer le screenshot de ce projet).
Une fois le fichier dot créé, il suffit de taper: dot -Tpng fichier.dot > fichier.png (dot nécessite le paquet "graphviz").
Pour compiler le projet, il suffit simplement de taper "make" (ou alors "make debug" si on souhaite développer sur ce projet).
Le make va créer les 3 exécutables. Le Makefile, par défaut, n'utilise pas de C++11. Il faudra éditer le champs CFLAGS pour qu'il le fasse.
Sans C++11, le hash set (le std::unordered_map) ne sera pas géré, et ne fera donc pas parti du bench.
Le projet est normalement compatible C++03 et supérieur, et portable sur les plateformes Windows, Linux et Mac.
=== Métriques ===
En prenant un dictionnaire des mots de la langue françaises (récupéré ici: http://www.pallier.org/ressources/dicofr/liste.de.mots.francais.frgut.txt), composé de 336531 mots et faisant 3.6 Mo, on effectue les opérations suivantes:
- On regarde pour chaque collection chargée, la mémoire utilisée.
- On charge le dictionnaire dans la collection, et on mesure le temps de chargement.
- On recherche tous les mots du dictionnaire dans la collection, et on mesure le temps de recherche.
On obtient alors les différentes métriques ci-dessous.
En utilisant un std::string comme conteneur:
Sans surprise, le std::vector est celui qui prend le moins de place. C'est aussi celui qui a le moins d'overhead. Comme on effecture une recherche binaire, il est nécessaire de le trier, ce qui fait exploser son temps de chargement par rapport aux autres collections. Son temps de recherche est assez similaire aux autres.
Le radix est, contre-intuitivement, celui qui prend le plus de place en mémoire ! Ça s'explique par le fait qu'il possède beaucoup de "petits noeuds" dû aux découpages de l'arbre, ce qui créer un gros overhead. Son temps de recherche est légèrement meilleur que les autres (hormis le hashset).
Le hashset (std::unordered_set) est de loin le conteneur le plus rapide. Ça s'explique par sa complexité algorithmique de recherche en 0(1) contre O(log n) pour tous les autres algorithmes. Néanmoins, sur des collections plus grosses, son empreinte mémoire grossirait beaucoup plus que le radix. De plus, contrairement aux autres collections qui sont triées, il ne serait pas possible d'obtenir la liste des mots commençant par celui fourni, sans faire un parcours total du hash (ce qui serait bien trop lent).
En utilisant un Core::SharedString comme conteneur:
Le Core::SharedString est une classe fournie avec ce projet, qui permet de regrouper en mémoire les chaînes identiques. Ainsi, avoir plusieurs doublons d'un même mot ne coûte pratiquement rien.
Au niveau mémoire, on voit que toutes les collections prennent plus de place (ce qui est normal, le SharedString a un overhead par rapport au std::string). Comme la plupart des collections ne découpe pas les mots, cette classe ne leur profite pas du tout (les mots du dictionnaires étant uniques, il n'y a jamais de doublons).
En revanche, le radix qui possède une multitude de petits morceaux de mots souvent identiques, profite énormément de cette optimisation, et descend drastiquement sa consommation mémoire.
Au niveau du temps de chargement et de recherche, c'est plus long, toujours à cause de l'overhead de cette classe. Le hashset voit ses performances chuter, à cause de l'indirection introduite dans le calcul de la clé de hash.
Clairement, le conteneur SharedString ne profite qu'à une collection qui peut en tirer parti.
Résumé meilleurs temps:
En comparant chacune des structures avec le conteneur le plus adapté, on voit que le radix s'en sort très bien. Peu de consommation mémoire, et un temps de recherche court.
=== Pistes d'amélioration ===
On pourrait améliorer le temps de chargement dans le radix, on fixant une taille fixe aux listes de noeuds (au dépit de la consommation mémoire).
On pourrait améliorer la consommation mémoire dans le radix, en utilisant autre chose que des std::vector dans les listes de noeuds (le std::vector a une fâcheuse tendance à doubler sa capacité interne une fois rempli) au dépit potentiellement de la vitesse.
=== Principe ===
Un Radix Tree est un Trie Tree amélioré. Cette structure de donnée permet de faire tenir une liste de mots dans un arbre compact. C'est très utilisé pour des dictionnaires, des numéros de téléphones, etc...
Sa fonction première est de dire si un mot est présent dans la collection, mais c'est aussi souvent employé pour faire de la complétion (c'est-à-dire donner tous les mots commençant par celui que l'on vient de fournir).
Par exemple pour les mots:
- tete
- testons
- testosterone
- testa
- tester
Le trie tree associé serait:
t
|
e
/ \
t s
/ \
e t
/ | \
o a e
/ \ \
n s r
/ \
s t
e
r
o
n
e
Et le radix tree:
te
/ \
te st
/ | \
o er a
/ \
ns sterone
=== Projet ===
Ce projet est composé de 3 exécutables:
- radix-completion: Lorsqu'on lui fournit un mot, il dit si celui-ci est présent dans le dictionnaire fourni et il donne la liste des mots qui commencent par celui-ci.
- radix-test: Tests unitaires pour vérifier que la collection a été implémentée correctement.
- radix-bench: Teste les performances de différentes collections (utilisé pour fournir les données ci-dessous).
À noter qu'il est possible de générer un fichier *.dot de l'arbre, afin de le faire dessiner par dotty (d'ailleurs utilisé pour créer le screenshot de ce projet).
Une fois le fichier dot créé, il suffit de taper: dot -Tpng fichier.dot > fichier.png (dot nécessite le paquet "graphviz").
Pour compiler le projet, il suffit simplement de taper "make" (ou alors "make debug" si on souhaite développer sur ce projet).
Le make va créer les 3 exécutables. Le Makefile, par défaut, n'utilise pas de C++11. Il faudra éditer le champs CFLAGS pour qu'il le fasse.
Sans C++11, le hash set (le std::unordered_map) ne sera pas géré, et ne fera donc pas parti du bench.
Le projet est normalement compatible C++03 et supérieur, et portable sur les plateformes Windows, Linux et Mac.
=== Métriques ===
En prenant un dictionnaire des mots de la langue françaises (récupéré ici: http://www.pallier.org/ressources/dicofr/liste.de.mots.francais.frgut.txt), composé de 336531 mots et faisant 3.6 Mo, on effectue les opérations suivantes:
- On regarde pour chaque collection chargée, la mémoire utilisée.
- On charge le dictionnaire dans la collection, et on mesure le temps de chargement.
- On recherche tous les mots du dictionnaire dans la collection, et on mesure le temps de recherche.
On obtient alors les différentes métriques ci-dessous.
En utilisant un std::string comme conteneur:
+---------------+--------+----------+------------+ | NORMAL | Memory | LoadTime | SearchTime | +---------------+--------+----------+------------+ | sorted vector | 12 Mo |127+371 ms| 233 ms | | radix | 22 Mo | 331 ms | 190 ms | | set | 18 Mo | 356 ms | 219 ms | | map | 21 Mo | 415 ms | 222 ms | | hashset | 18 Mo | 274 ms | 76 ms | +---------------+--------+----------+------------+
Sans surprise, le std::vector est celui qui prend le moins de place. C'est aussi celui qui a le moins d'overhead. Comme on effecture une recherche binaire, il est nécessaire de le trier, ce qui fait exploser son temps de chargement par rapport aux autres collections. Son temps de recherche est assez similaire aux autres.
Le radix est, contre-intuitivement, celui qui prend le plus de place en mémoire ! Ça s'explique par le fait qu'il possède beaucoup de "petits noeuds" dû aux découpages de l'arbre, ce qui créer un gros overhead. Son temps de recherche est légèrement meilleur que les autres (hormis le hashset).
Le hashset (std::unordered_set) est de loin le conteneur le plus rapide. Ça s'explique par sa complexité algorithmique de recherche en 0(1) contre O(log n) pour tous les autres algorithmes. Néanmoins, sur des collections plus grosses, son empreinte mémoire grossirait beaucoup plus que le radix. De plus, contrairement aux autres collections qui sont triées, il ne serait pas possible d'obtenir la liste des mots commençant par celui fourni, sans faire un parcours total du hash (ce qui serait bien trop lent).
En utilisant un Core::SharedString comme conteneur:
+---------------+--------+----------+------------+ | COMPACT | Memory | LoadTime | SearchTime | +---------------+--------+----------+------------+ | sorted vector | 20 Mo |655+424 ms| 234 ms | | radix | 14 Mo | 784 ms | 199 ms | | set | 26 Mo | 464 ms | 424 ms | | map | 29 Mo | 496 ms | 419 ms | | hashset | 26 Mo | 614 ms | 455 ms | +---------------+--------+----------+------------+
Le Core::SharedString est une classe fournie avec ce projet, qui permet de regrouper en mémoire les chaînes identiques. Ainsi, avoir plusieurs doublons d'un même mot ne coûte pratiquement rien.
Au niveau mémoire, on voit que toutes les collections prennent plus de place (ce qui est normal, le SharedString a un overhead par rapport au std::string). Comme la plupart des collections ne découpe pas les mots, cette classe ne leur profite pas du tout (les mots du dictionnaires étant uniques, il n'y a jamais de doublons).
En revanche, le radix qui possède une multitude de petits morceaux de mots souvent identiques, profite énormément de cette optimisation, et descend drastiquement sa consommation mémoire.
Au niveau du temps de chargement et de recherche, c'est plus long, toujours à cause de l'overhead de cette classe. Le hashset voit ses performances chuter, à cause de l'indirection introduite dans le calcul de la clé de hash.
Clairement, le conteneur SharedString ne profite qu'à une collection qui peut en tirer parti.
Résumé meilleurs temps:
+---------------+--------+----------+------------+ | SUMMARY | Memory | LoadTime | SearchTime | +---------------+--------+----------+------------+ | hashset | 18 Mo | 274 ms | 76 ms | | compact radix | 14 Mo | 784 ms | 199 ms | | set | 18 Mo | 356 ms | 219 ms | | map | 21 Mo | 415 ms | 222 ms | | sorted vector | 12 Mo |127+371 ms| 233 ms | +---------------+--------+----------+------------+
En comparant chacune des structures avec le conteneur le plus adapté, on voit que le radix s'en sort très bien. Peu de consommation mémoire, et un temps de recherche court.
=== Pistes d'amélioration ===
On pourrait améliorer le temps de chargement dans le radix, on fixant une taille fixe aux listes de noeuds (au dépit de la consommation mémoire).
On pourrait améliorer la consommation mémoire dans le radix, en utilisant autre chose que des std::vector dans les listes de noeuds (le std::vector a une fâcheuse tendance à doubler sa capacité interne une fois rempli) au dépit potentiellement de la vitesse.
Codes Sources
A voir également
- Completion de texte via un Radix Tree
- Source tree - Conseils pratiques -[Fiches pratiques]
- Texte à compléter ✓ - Forum VBA Office (Excel, Word ...)
- Roulettechat texte - Forum PHP
- Texte aléatoire - Forum Visual Basic
- Tri radix ✓ - Forum Delphi / Pascal
Vous n'êtes pas encore membre ?
inscrivez-vous, c'est gratuit et ça prend moins d'une minute !
Les membres obtiennent plus de réponses que les utilisateurs anonymes.
Le fait d'être membre vous permet d'avoir un suivi détaillé de vos demandes et codes sources.
Le fait d'être membre vous permet d'avoir des options supplémentaires.