


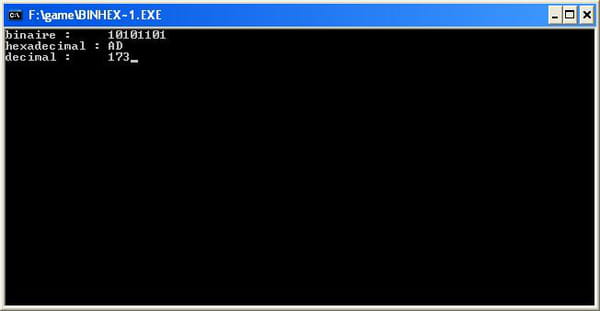
Conversion binaire/decimal/hexadecimal - tres simple [djgpp]
Description
Tout le monde fait des fonctions complique pour comparer des nombres avec des puissances de deux mais il y a une maniere beaucoup plus simple avec les unions
voila c'est vraiment pas complique
Source / Exemple :
#include <stdio.h> /* pour printf */ #include <conio.h> /* pour getch */ /* Nouveau type de char, il prend exactement la meme place en memoire qu'un vrai char. C'est une union donc chaque membre de la structure occupera la meme place en memoire.
- /
- /
Conclusion :
voila c'est vraiment pas complique
Codes Sources
A voir également
- Conversion binaire/decimal/hexadecimal - tres simple [djgpp]
- Decimal sql - Forum SQL
- Conversion hexadecimal en decimal - Forum C / C++ / C++.NET
- Couleur hexadecimal - Forum C# / .NET
- Deux chiffre aprèla virgule - Forum SQL
- Conversion binaire decimal ✓ - Forum Delphi / Pascal
Vous n'êtes pas encore membre ?
inscrivez-vous, c'est gratuit et ça prend moins d'une minute !
Les membres obtiennent plus de réponses que les utilisateurs anonymes.
Le fait d'être membre vous permet d'avoir un suivi détaillé de vos demandes et codes sources.
Le fait d'être membre vous permet d'avoir des options supplémentaires.