


Traitement de l'image: filtre médian en temps constant
Description
Le filtre médian est un filtre, spatial et non linéaire, qui calcule en chaque pixel la médiane des niveaux de gris des pixels de sa fenêtre, ce qui donnera le niveau de gris du pixel dans l'image filtrée.
Imaginons une fenêtre de taille r, pour trouver la médiane, il faut trier les pixels et retenir le pixel médian. Si on programme cette fonction d'une manière naïve, on devra pour chaque pixel trier les r pixels voisins. La complexité de cet algorithme explose lorsque r augmente trop.
Cet algorithme propose une méthode pour calculer le filtre médian avec un temps constant pour tout r ! Quelque soit la taille de la fenêtre, la complexité reste la même!
Cet algorithme n'est pas de moi mais il est tellement performant qu'il devait être sur Codes Sources. Voici le lien du site internet des créateurs:
http://nomis80.org/ctmf.html
Vous trouverez aussi sur ce site internet, le très intéressant document technique de cet algorithme.
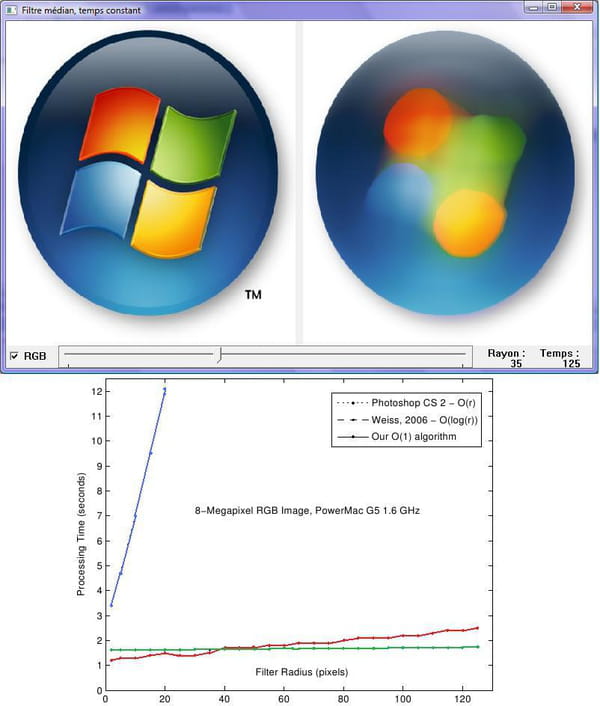
Si vous n'êtes pas convaincu, j'ai créé une petite interface graphique qui permet d'appliquer le filtre médian sur des images. Vous pouvez ainsi modifier r (presque) en temps réel.
Le traitement des images couleurs est simple mais pourrait être amélioré: je lance 3 fois l'algorithme suivant les composantes R,G et B. On peut donc choisir de filtrer en couleur ou en niveau de gris. On peut aussi voir le temps de l'exécution de la fonction en bas à droite de la fenêtre.
Pour sélectionner une autre image, il suffit de faire un clic droit sur l'image.
J'insiste, allez visiter leur site internet.
Sources : http://nomis80.org/ctmf.html
Imaginons une fenêtre de taille r, pour trouver la médiane, il faut trier les pixels et retenir le pixel médian. Si on programme cette fonction d'une manière naïve, on devra pour chaque pixel trier les r pixels voisins. La complexité de cet algorithme explose lorsque r augmente trop.
Cet algorithme propose une méthode pour calculer le filtre médian avec un temps constant pour tout r ! Quelque soit la taille de la fenêtre, la complexité reste la même!
Cet algorithme n'est pas de moi mais il est tellement performant qu'il devait être sur Codes Sources. Voici le lien du site internet des créateurs:
http://nomis80.org/ctmf.html
Vous trouverez aussi sur ce site internet, le très intéressant document technique de cet algorithme.
Si vous n'êtes pas convaincu, j'ai créé une petite interface graphique qui permet d'appliquer le filtre médian sur des images. Vous pouvez ainsi modifier r (presque) en temps réel.
Le traitement des images couleurs est simple mais pourrait être amélioré: je lance 3 fois l'algorithme suivant les composantes R,G et B. On peut donc choisir de filtrer en couleur ou en niveau de gris. On peut aussi voir le temps de l'exécution de la fonction en bas à droite de la fenêtre.
Pour sélectionner une autre image, il suffit de faire un clic droit sur l'image.
J'insiste, allez visiter leur site internet.
Source / Exemple :
/*
- ctmf.c - Constant-time median filtering
- Copyright (C) 2006 Simon Perreault
- Reference: S. Perreault and P. Hébert, "Median Filtering in Constant Time",
- IEEE Transactions on Image Processing, September 2007.
- This program has been obtained from http://nomis80.org/ctmf.html. No patent
- covers this program, although it is subject to the following license:
- This program is free software: you can redistribute it and/or modify
- it under the terms of the GNU General Public License as published by
- the Free Software Foundation, either version 3 of the License, or
- (at your option) any later version.
- This program is distributed in the hope that it will be useful,
- but WITHOUT ANY WARRANTY; without even the implied warranty of
- MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
- GNU General Public License for more details.
- You should have received a copy of the GNU General Public License
- along with this program. If not, see <http://www.gnu.org/licenses/>.
- Contact:
- Laboratoire de vision et systèmes numériques
- Pavillon Adrien-Pouliot
- Université Laval
- Sainte-Foy, Québec, Canada
- G1K 7P4
- perreaul@gel.ulaval.ca
- /
- This structure represents a two-tier histogram. The first tier (known as the
- "coarse" level) is 4 bit wide and the second tier (known as the "fine" level)
- is 8 bit wide. Pixels inserted in the fine level also get inserted into the
- coarse bucket designated by the 4 MSBs of the fine bucket value.
- The structure is aligned on 16 bytes, which is a prerequisite for SIMD
- instructions. Each bucket is 16 bit wide, which means that extra care must be
- taken to prevent overflow.
- /
- HOP is short for Histogram OPeration. This macro makes an operation \a op on
- histogram \a h for pixel value \a x. It takes care of handling both levels.
- /
- ((uint16_t*) h.fine + x) op;
- Adds histograms \a x and \a y and stores the result in \a y. Makes use of
- SSE2, MMX or Altivec, if available.
- /
- (__m128i*) &y[0] = _mm_add_epi16( *(__m128i*) &y[0], *(__m128i*) &x[0] );
- (__m128i*) &y[8] = _mm_add_epi16( *(__m128i*) &y[8], *(__m128i*) &x[8] );
- (__m64*) &y[0] = _mm_add_pi16( *(__m64*) &y[0], *(__m64*) &x[0] );
- (__m64*) &y[4] = _mm_add_pi16( *(__m64*) &y[4], *(__m64*) &x[4] );
- (__m64*) &y[8] = _mm_add_pi16( *(__m64*) &y[8], *(__m64*) &x[8] );
- (__m64*) &y[12] = _mm_add_pi16( *(__m64*) &y[12], *(__m64*) &x[12] );
- (vector unsigned short*) &y[0] = vec_add( *(vector unsigned short*) &y[0], *(vector unsigned short*) &x[0] );
- (vector unsigned short*) &y[8] = vec_add( *(vector unsigned short*) &y[8], *(vector unsigned short*) &x[8] );
- Subtracts histogram \a x from \a y and stores the result in \a y. Makes use
- of SSE2, MMX or Altivec, if available.
- /
- (__m128i*) &y[0] = _mm_sub_epi16( *(__m128i*) &y[0], *(__m128i*) &x[0] );
- (__m128i*) &y[8] = _mm_sub_epi16( *(__m128i*) &y[8], *(__m128i*) &x[8] );
- (__m64*) &y[0] = _mm_sub_pi16( *(__m64*) &y[0], *(__m64*) &x[0] );
- (__m64*) &y[4] = _mm_sub_pi16( *(__m64*) &y[4], *(__m64*) &x[4] );
- (__m64*) &y[8] = _mm_sub_pi16( *(__m64*) &y[8], *(__m64*) &x[8] );
- (__m64*) &y[12] = _mm_sub_pi16( *(__m64*) &y[12], *(__m64*) &x[12] );
- (vector unsigned short*) &y[0] = vec_sub( *(vector unsigned short*) &y[0], *(vector unsigned short*) &x[0] );
- (vector unsigned short*) &y[8] = vec_sub( *(vector unsigned short*) &y[8], *(vector unsigned short*) &x[8] );
- \brief Constant-time median filtering
- This function does a median filtering of an 8-bit image. The source image is
- processed as if it was padded with zeros. The median kernel is square with
- odd dimensions. Images of arbitrary size may be processed.
- To process multi-channel images, you must call this function multiple times,
- changing the source and destination adresses and steps such that each channel
- is processed as an independent single-channel image.
- Processing images of arbitrary bit depth is not supported.
- The computing time is O(1) per pixel, independent of the radius of the
- filter. The algorithm's initialization is O(r*width), but it is negligible.
- Memory usage is simple: it will be as big as the cache size, or smaller if
- the image is small. For efficiency, the histograms' bins are 16-bit wide.
- This may become too small and lead to overflow as \a r increases.
- \param src Source image data.
- \param dst Destination image data. Must be preallocated.
- \param width Image width, in pixels.
- \param height Image height, in pixels.
- \param src_step Distance between adjacent pixels on the same column in
- the source image, in bytes.
- \param dst_step Distance between adjacent pixels on the same column in
- the destination image, in bytes.
- \param r Median filter radius. The kernel will be a 2*r+1 by
- 2*r+1 square.
- \param cn Number of channels. For example, a grayscale image would
- have cn=1 while an RGB image would have cn=3.
- \param memsize Maximum amount of memory to use, in bytes. Set this to
- the size of the L2 cache, then vary it slightly and
- measure the processing time to find the optimal value.
- For example, a 512 kB L2 cache would have
- memsize=512*1024 initially.
- /
- Processing the image in vertical stripes is an optimization made
- necessary by the limited size of the CPU cache. Each histogram is 544
- bytes big and therefore I can fit a limited number of them in the cache.
- That number may sometimes be smaller than the image width, which would be
- the number of histograms I would need without stripes.
- I need to keep histograms in the cache so that they are available
- quickly when processing a new row. Each row needs access to the previous
- row's histograms. If there are too many histograms to fit in the cache,
- thrashing to RAM happens.
- To solve this problem, I figure out the maximum number of histograms
- that can fit in cache. From this is determined the number of stripes in
- an image. The formulas below make the stripes all the same size and use
- as few stripes as possible.
- Note that each stripe causes an overlap on the neighboring stripes, as
- when mowing the lawn. That overlap is proportional to r. When the overlap
- is a significant size in comparison with the stripe size, then we are not
- O(1) anymore, but O(r). In fact, we have been O(r) all along, but the
- initialization term was neglected, as it has been (and rightly so) in B.
- Weiss, "Fast Median and Bilateral Filtering", SIGGRAPH, 2006. Processing
- by stripes only makes that initialization term bigger.
- Also, note that the leftmost and rightmost stripes don't need overlap.
- A flag is passed to ctmf_helper() so that it treats these cases as if the
- image was zero-padded.
- /
Conclusion :
Sources : http://nomis80.org/ctmf.html
Codes Sources
A voir également
- Traitement de l'image: filtre médian en temps constant
- Traitement image - Conseils pratiques -Java
- Fpdf image ✓ - Forum PHP
- Vectoriser une image photoshop ✓ - Forum Graphisme/design
- Inverser une image photoshop - Forum Graphisme/design
- Form image ✓ - Forum Visual Basic
Du même auteur (Pistol_Pete)
-
Visualisation des images en 3d sans opengl
-
Analyse de la texture d'une image : filtre de gabor
-
Viewer complet pour le traitement de l'image : imanalyse
-
Algorithmes d'optimisation non linéaire: descente de gradient, lm, bfgs, simplexe...
-
Classe graph: gestion des graphiques dans les applications win32
Vous n'êtes pas encore membre ?
inscrivez-vous, c'est gratuit et ça prend moins d'une minute !
Les membres obtiennent plus de réponses que les utilisateurs anonymes.
Le fait d'être membre vous permet d'avoir un suivi détaillé de vos demandes et codes sources.
Le fait d'être membre vous permet d'avoir des options supplémentaires.