


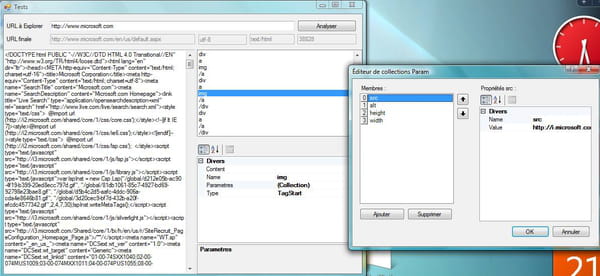
Parseur html
Description
Je mets ce ptit bout de code en vue de remarques...
Ca parse le Html, j'ai fais quelques tests sur des pages bien codées et sur des très mal codés... ca à l'air de marcher.
Ca parse, mais ca ne créer pas un arbre DOM, le parseur renvoie par itération une liste d'objet Tag.
Y a aussi du gadjet au niveau du constructeur pour envoyer soit un fichier, soit un url à parser, une fonction pour construire une url à partir de l'url de la page, et le reconstructeur de page(propre et pas mal optimisé en taille).
J'ai fais ca dans le cadre de la refonte de mon ptit logiciel dont j'ai honte d'en parler (e-rus sitemap)... qui marche pas, ou pas bien, pas partout... une saloperie quoi.
Etant donné qu'en ce moment mon site est arrêté(pour cause de transit), j'en profite pour vous présenter ce qui me servirait de "moteur" d'exploration.
Je veux optimiser ca encore, soit par l'unsafe ou le refaire en c++ pour le traitement de la chaine Html, mais je sais pas si ca vaut le coup à ce niveau la.
Merci de vos remarques, ne soyez pas trop dur quand même
Ca parse le Html, j'ai fais quelques tests sur des pages bien codées et sur des très mal codés... ca à l'air de marcher.
Ca parse, mais ca ne créer pas un arbre DOM, le parseur renvoie par itération une liste d'objet Tag.
Y a aussi du gadjet au niveau du constructeur pour envoyer soit un fichier, soit un url à parser, une fonction pour construire une url à partir de l'url de la page, et le reconstructeur de page(propre et pas mal optimisé en taille).
J'ai fais ca dans le cadre de la refonte de mon ptit logiciel dont j'ai honte d'en parler (e-rus sitemap)... qui marche pas, ou pas bien, pas partout... une saloperie quoi.
Etant donné qu'en ce moment mon site est arrêté(pour cause de transit), j'en profite pour vous présenter ce qui me servirait de "moteur" d'exploration.
Je veux optimiser ca encore, soit par l'unsafe ou le refaire en c++ pour le traitement de la chaine Html, mais je sais pas si ca vaut le coup à ce niveau la.
Source / Exemple :
Voir le zip, la classe intéressante est trop longue pour être ici
Conclusion :
Merci de vos remarques, ne soyez pas trop dur quand même
Vous n'êtes pas encore membre ?
inscrivez-vous, c'est gratuit et ça prend moins d'une minute !
Les membres obtiennent plus de réponses que les utilisateurs anonymes.
Le fait d'être membre vous permet d'avoir un suivi détaillé de vos demandes et codes sources.
Le fait d'être membre vous permet d'avoir des options supplémentaires.