


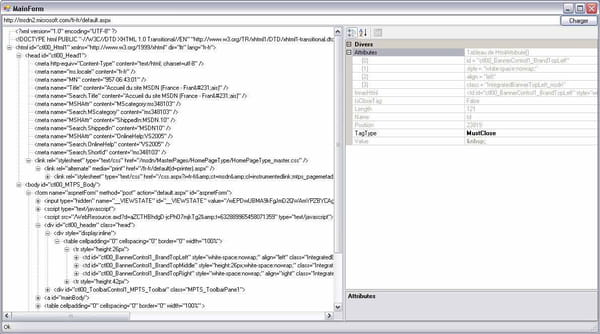
Parser html
Description
Ce code est une lib qui permet d'accéder la structure d'une page HTML
Sa tolérance sur la qualité du code HTML est certes inférieur aux navigateurs mais suffisent pour la plupart des applis ou je l'ai utilisé
Bientot quand le html sera bien formaté, on pourra utiliser un parseur xml mais pour l'instant... n'hésitez par à le tester et a me faire parvenir l'url des pages qui mettre ce code a genoux :(
Sa tolérance sur la qualité du code HTML est certes inférieur aux navigateurs mais suffisent pour la plupart des applis ou je l'ai utilisé
Source / Exemple :
(tout est dans le zip)
Conclusion :
Bientot quand le html sera bien formaté, on pourra utiliser un parseur xml mais pour l'instant... n'hésitez par à le tester et a me faire parvenir l'url des pages qui mettre ce code a genoux :(
Codes Sources
- bin
- obj
- _UpgradeReport_Files
- App.ico
- AssemblyInfo.cs
- HTML - Index, Liste des tags balises et des evenements.url
- HtmlAttribute.cs
- HtmlChars.cs
- HtmlDocument.cs
- HtmlMimeType.cs
- HtmlNode.cs
- HtmlParser.csproj
- HtmlParser.csproj.user
- HtmlParser.sln
- HtmlParser.suo
- HtmlTag.cs
- HtmlValue.cs
- MainClass.cs
- MainForm.cs
- MainForm.Designer.cs
- MainForm.resx
- regexp.TXT
- UpgradeLog.XML
A voir également
- Parser html
- Html array - Conseils pratiques -PHP
- Span html - Forum PHP
- Fermer balise html - Forum PHP
- Php html parser ✓ - Forum PHP
- Checkbox html ✓ - Forum PHP
Vous n'êtes pas encore membre ?
inscrivez-vous, c'est gratuit et ça prend moins d'une minute !
Les membres obtiennent plus de réponses que les utilisateurs anonymes.
Le fait d'être membre vous permet d'avoir un suivi détaillé de vos demandes et codes sources.
Le fait d'être membre vous permet d'avoir des options supplémentaires.